#KubeWeek Day 3 Kubernetes Workloads

The complete guide for Deployments, StatefulSets, DaemonSets, Jobs, and CronJobs
Kubernetes Workloads
Kubernetes workload refers to the set of tasks or applications that need to be deployed and managed on a Kubernetes cluster. Workloads can be anything from a simple web server to a complex distributed system consisting of multiple services, databases, and other components.
Kubernetes provides various workload resources to manage different types of applications, including Deployments, StatefulSets, DaemonSets, Jobs, and CronJobs.
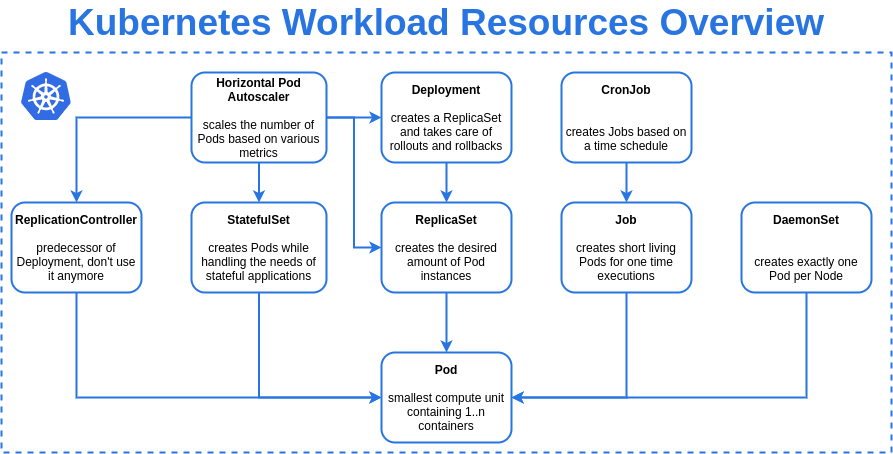
There are several advantages and features of Kubernetes workloads:
Scalability: Workloads in Kubernetes are designed to scale horizontally by creating multiple replicas of the same container. This allows you to handle increased traffic and workload on your application by adding more instances of the container.
Reliability: Workloads provide automatic failover and self-healing capabilities, ensuring that your application stays up and running even if one or more instances of the container fail. This is achieved through the use of replicas, health checks, and automatic restarts.
Automation: Workloads allow for the automation of application deployment, scaling, and management. You can define the desired state of your application and Kubernetes will automatically ensure that the current state matches the desired state, making it easier to manage large-scale applications.
Rolling Updates: Workloads provide the ability to perform rolling updates, allowing you to update your application with zero downtime. This is achieved by gradually updating the replicas of your container to the new version while keeping the old version running until the new version is fully deployed.
Stateful Applications: StatefulSets provide a way to manage stateful applications on Kubernetes. StatefulSets ensure that each replica of a container is created with a unique identity, and that data is persisted across restarts, making it possible to run stateful applications on Kubernetes.
Batch Processing: Jobs and CronJobs provide a way to run batch processing tasks and periodic jobs on Kubernetes. This is useful for running tasks such as backups, data processing, and periodic maintenance tasks.
Deployments
If we want to deploy an application then we have Pod. If we want to scale the application then we have ReplicaSet. Then what is Deployment and why do we need Deployment? This question comes to everyone’s mind.
Deployment sits on top of the Kubernetes hierarchy layer. First Pod, then ReplicaSet, and then Deployment. By using Deployment we can easily upgrade the Pod instances using rolling updates and we can easily undo the changes. So Deployment in the Kubernetes cluster is very flexible and gives us more value.

Deployment Features
Scalability: We can easily scale the application by creating multiple instances of a single Pod.
Rolling updates: Deployments allow you to perform rolling updates to your application, which means updating your application without any downtime. This is achieved by gradually updating the replicas of your container to the new version while keeping the old version running until the new version is fully deployed.
Scaling: Deployments make it easy to scale your application by simply increasing or decreasing the number of replicas. Kubernetes will automatically distribute the load across the replicas.
Rollback: If an update fails, Deployments provide a way to automatically roll back to the previous version of your application.
Self-healing: Deployments provide automatic failover and self-healing capabilities. If one or more instances of the container fail, Kubernetes will automatically restart the failed instances and ensure that the desired number of replicas are running.
Versioning: Deployments provide versioning for your application. You can easily roll back to a previous version if there are issues with the current version.
Replication: Deployments provide the ability to create multiple replicas of your application. This ensures that your application is highly available and can handle increased traffic.
Create Deployment YAML File
apiVersion: apps/v1
kind: Deployment
metadata:
name: reddit-clone-deployment
labels:
app: reddit-clone
spec:
replicas: 2
selector:
matchLabels:
app: reddit-clone
template:
metadata:
labels:
app: reddit-clone
spec:
containers:
- name: reddit-clone
image: dushyantkumark/reddit-clone-k8s-ingress
ports:
- containerPort: 3000
Steps to deploy a Deployment in a Kubernetes cluster
Clone this repository to your local machine:
git clonehttps://github.com/dushyantkumark/reddit-clone-k8s-ingressNavigate to the project directory:
cd reddit-clone-k8s-ingressBuild the Docker image for the Reddit clone app
docker build -t reddit-clone.Deploy the app to Kubernetes:
kubectl apply -f deployment.yamlCheck the status of the Deployment using the
kubectl get deploymentscommand.Verify that the Pods are running using the
kubectl get podscommand.
StatefulSets
StatefulSets are used for deploying stateful applications that require stable network identities and persistent data. StatefulSets provide guarantees about the ordering and uniqueness of pods, making them suitable for applications like databases or distributed systems that rely on stable network hostnames or persistent volumes.
StatefulSets Features
Stable network identities: StatefulSets provide stable network identities for each pod, which makes it possible to run stateful applications on Kubernetes. Each pod is assigned a unique hostname and a persistent network identity that does not change even if the pod is deleted or rescheduled.
Ordered deployment: StatefulSets allow you to control the order in which pods are deployed and terminated. This is important for stateful applications that require specific dependencies to be running before they can start.
Stateful container replicas: StatefulSets ensure that each replica of a container is created with a unique identity, and that data is persisted across restarts. This makes it possible to run stateful applications such as databases, message queues, and file systems on Kubernetes.
Scaling: StatefulSets provide the ability to scale your stateful application by increasing or decreasing the number of replicas. Kubernetes will ensure that each new replica is created with a unique identity and that data is properly replicated across all replicas.
Updating: StatefulSets provide the ability to update your stateful application with minimal downtime. You can update one replica at a time while ensuring that the remaining replicas are still serving requests.
Headless services: StatefulSets also provide the ability to create headless services, which allow you to access each pod directly by its hostname. This is useful for stateful applications that require direct communication between pods, such as databases.
Create a StatefulSet manifest file
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: mongodb
spec:
replicas: 3
selector:
matchLabels:
app: mongodb
template:
metadata:
labels:
app: mongodb
spec:
containers:
- name: mongodb
image: mongo:4.4
ports:
- containerPort: 27017
volumeMounts:
- name: data
mountPath: /data/db
volumeClaimTemplates:
- metadata:
name: data
spec:
storageClassName: standard
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
selector: matchLabels: app: mongodb: This specifies the label selector for the StatefulSet. It will match any Pods with the labelapp=mongodb.template: metadata: labels: app: mongodb: This specifies the labels for the Pod template that will be used to create the Pods.spec: containers: - name: mongodb: This specifies the name of the container running in the Pod template.image: mongo:4.4: This specifies the Docker image to use for the container.ports: - containerPort: 27017: This specifies the port that the container will listen on.volumeMounts: - name: data mountPath: /data/db: This specifies a volume mount for the container, which will mount a volume nameddataat the path/data/db.volumeClaimTemplates: - metadata: name: data: This specifies a Persistent Volume Claim (PVC) template for thedatavolume.spec: storageClassName: standard: This specifies the storage class to use for the PVC.accessModes: - ReadWriteOnce: This specifies the access mode for the PVC. In this case, it is set toReadWriteOnce, which means the volume can be mounted by a single node at a time.resources: requests: storage: 1Gi: This specifies the amount of storage to request for the PVC. In this case, it is set to1Gi
Steps To run this StatefulSet manifest file
Open a terminal or command prompt and navigate to the directory where you want to save the manifest file.
Create a manifest file using
vim mongodb-statefulset.yaml.Make sure you have
kubectlinstalled and configured to connect to your Kubernetes cluster. You can check this by runningkubectl version.Apply the manifest file to your cluster by running the following command:
Copy codekubectl apply -f mongodb-statefulset.yamlThis will create the StatefulSet and any associated resources (such as Pods and Persistent Volume Claims) in your cluster.
You can monitor the status of the StatefulSet and its Pods by running the following commands:
arduinoCopy codekubectl get statefulset mongodb kubectl get pods -l app=mongodbThis will show you the current status of the StatefulSet and its Pods.
Once the StatefulSet is running, you can interact with the MongoDB instances by connecting to the Pods directly. You can do this by running the following command:
phpCopy codekubectl port-forward <mongodb-pod-name> 27017This will forward port 27017 from the specified MongoDB Pod to your machine. You can then connect to the MongoDB instance using a MongoDB client.
DaemonSets
DaemonSets are another type of workload in Kubernetes that are used to ensure that a particular Pod is running on all or a subset of nodes in a cluster. A DaemonSet creates a Pod on each node in the cluster and ensures that the Pod is always running.
DaemonSets Features
A DaemonSet ensures that a specific Pod is running on all (or a subset of) nodes in a Kubernetes cluster.
DaemonSets can be used to deploy system-level agents, such as logging agents, monitoring agents, or networking agents.
When a new node is added to the cluster, the DaemonSet ensures that the necessary Pods are created on the new node automatically.
When a node is removed from the cluster, the DaemonSet ensures that the Pods running on that node are terminated.
Create DaemonSet manifest file
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: nginx
spec:
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:latest
ports:
- containerPort: 80
spec: selector: matchLabels: app: nginx: This specifies the label selector for the DaemonSet. It will match any nodes with the labelapp=nginx.template: metadata: labels: app: nginx: This specifies the labels for the Pod template that will be used to create the Pods.spec: containers: - name: nginx: This specifies the name of the container running in the Pod template.image: nginx:latest: This specifies the Docker image to use for the container.ports: - containerPort: 80: This specifies the port that the container will listen on.
Steps to run this DaemonSet manifest file:
Open a terminal or command prompt and navigate to the directory where you want to save the manifest file.
Create a file using Vim editor
vim nginx-daemonset.yamlwith.yamlor.ymlextension.Make sure you have
kubectlinstalled and configured to connect to your Kubernetes cluster. You can check this by runningkubectl version.Apply the manifest file to your cluster by running the following command:
Copy codekubectl apply -f nginx-daemonset.yamlThis will create the DaemonSet and any associated resources (such as Pods) in your cluster.
You can monitor the status of the DaemonSet and its Pods by running the following commands:
arduinoCopy codekubectl get daemonset nginx kubectl get pods -l app=nginxThis will show you the current status of the DaemonSet and its Pods.
Jobs
Job is a type of workload that creates one or more Pods and ensures that they complete successfully. A Job is useful for running batch processes, such as data processing or backups, that only need to run once or on a scheduled basis. Once the Job's task is complete, the Pod(s) will terminate automatically.
Jobs features
A Job creates one or more Pods that run a specific task or batch job.
A Job ensures that the Pods complete successfully before terminating.
A Job can be run once or on a scheduled basis, using a CronJob.
A Job can be configured to automatically restart failed Pods.
Create a Job manifest file
apiVersion: batch/v1
kind: Job
metadata:
name: example-job
spec:
template:
spec:
containers:
- name: example-job-container
image: busybox:latest
command: ["echo", "Hello, Kubernetes!"]
restartPolicy: Never
backoffLimit: 4
spec: template: spec: containers: - name: example-job-container: This specifies the name of the container running in the Pod template.image: busybox:latest: This specifies the Docker image to use for the container.command: ["echo", "Hello, Kubernetes!"]: This specifies the command to run in the container.restartPolicy: Never: This specifies that the Pod(s) created by the Job should not be restarted if they fail.backoffLimit: 4: This specifies the number of times the Job should be retried if it fails.
Steps to create and run this Job
Open a terminal or command prompt and navigate to the directory where you want to save the manifest file.
Create a file using Vim editor
vim example-job.yamlwith.yamlor.ymlextension.Make sure you have
kubectlinstalled and configured to connect to your Kubernetes cluster. You can check this by runningkubectl version.Apply the manifest file to your cluster by running the following command:
Copy codekubectl apply -f example-job.yamlThis will create the Job and any associated resources (such as Pods) in your cluster.
You can monitor the status of the Job and its Pods by running the following commands:
arduinoCopy codekubectl get jobs kubectl logs example-job-xxxxxxxxxxReplace
xxxxxxxxxxwith the unique identifier for the Pod(s) created by the Job. Thelogscommand will display the output from theechocommand in the container.
This is how you can run the job in your kubernetes cluster.
CronJobs
CronJobs are used for running scheduled tasks on a Kubernetes cluster. CronJobs are similar to Jobs, but they allow you to specify a cron-like schedule to run the task at specific times or intervals. CronJobs can be used to automate repetitive or periodic tasks, such as backups, cleaning up old data, or sending notifications.
CronJobs features
A CronJob creates Jobs on a schedule, based on a specified cron-like schedule string.
A CronJob can be used to run Jobs at specific times, such as every day at 3 am.
A CronJob can be used to run Jobs at specific intervals, such as every hour or every week.
A CronJob can be configured to automatically clean up old Jobs and associated resources.
Create CronJob manifest file
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: example-cronjob
spec:
schedule: "0 5 * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: example-cronjob-container
image: busybox:latest
command: ["echo", "Hello, Kubernetes from CronJob!"]
restartPolicy: Never
successfulJobsHistoryLimit: 3
failedJobsHistoryLimit: 2
spec: schedule: "0 5 * * *": This specifies the cron-like schedule for the CronJob. In this example, the Job will run every day at 5 amrestartPolicy: Never: This specifies that the Pod(s) created by the Job should not be restarted if they fail.successfulJobsHistoryLimit: 3: This specifies the number of successful Jobs to keep in history.failedJobsHistoryLimit: 2: This specifies the number of failed Jobs to keep in the history.
Steps to create and run this cronjob
Open a terminal or command prompt and navigate to the directory where you want to save the manifest file.
Create a file using Vim editor
vim example-cronjob.yamlwith.yamlor.ymlextension.Apply the manifest file to your cluster by running the following command:
Copy codekubectl apply -f example-cronjob.yamlThis will create the CronJob and any associated resources (such as Jobs) in your cluster.
You can monitor the status of the CronJob and its Jobs by running the following commands:
arduinoCopy codekubectl get cronjobs
Conclusion: In conclusion, Kubernetes workloads provide a powerful set of tools for deploying and managing containerized applications on a Kubernetes cluster. Deployments, StatefulSets, DaemonSets, Jobs, and CronJobs are all designed to handle specific use cases, providing scalability, reliability, and automation for modern cloud-native applications.
\...................................................................................................................................................
The above information is up to my understanding. Suggestions are always welcome.
#Kubernetes #DevOps #90daysofdevops #KubeWeek
Shubham Londhe Sir
Follow for many such contents:




