AWS S3: Simple Storage Service with Handson Lab

🌟 Introduction
S3 offers virtually unlimited storage capacity, high durability, and availability, ensuring data protection and accessibility. It integrates well with other AWS services and provides robust security features to control access and encrypt data. S3 is widely used by individuals and businesses to store various types of files, making it a popular choice for data storage and backup in the cloud.

🌟 What is AWS S3?
Amazon Simple Storage Service (Amazon S3) is a highly scalable and reliable cloud storage service provided by Amazon Web Services (AWS). It offers a simple web services interface that allows individuals and businesses to store and retrieve any amount of data from anywhere on the web.
With AWS S3, you can store and retrieve data objects such as images, videos, documents, and any other type of file. It provides virtually unlimited storage capacity, allowing you to store as much data as you need without worrying about capacity constraints.
S3 offers durability, ensuring that your data is stored redundantly across multiple devices and facilities within an AWS Region. This redundancy minimizes the risk of data loss due to hardware failures or disasters. It also provides high availability, enabling you to access your data whenever you need it.
One of the key advantages of S3 is its scalability. You can start with a small amount of storage and easily expand it as your needs grow. S3 seamlessly handles the increased storage requirements without any disruption to your applications or workflows.
S3 also offers robust security features to protect your data. You can manage access to your data using AWS Identity and Access Management (IAM) policies, bucket policies, and Access Control Lists (ACLs). Additionally, you can enable server-side encryption to ensure the confidentiality of your data.
AWS S3 integrates well with other AWS services, allowing you to build scalable and cost-effective solutions. For example, you can use S3 with AWS Lambda for serverless computing, Amazon CloudFront for content delivery, or Amazon Athena for data analytics.
🌟 Why do we need AWS S3?
There are several reasons why businesses and individuals may need AWS S3 (Amazon Simple Storage Service):
Scalable Storage: AWS S3 provides virtually unlimited storage capacity, allowing businesses to store and retrieve large amounts of data as their needs grow. It eliminates the need for investing in and managing on-premises storage infrastructure.
Data Backup and Recovery: S3 is an excellent solution for data backup and recovery. It offers high durability, storing data redundantly across multiple devices and facilities. This reduces the risk of data loss and provides reliable backup options for critical business data.
Cost-Effective: AWS S3 follows a pay-as-you-go model, where you only pay for the storage and bandwidth you use. There are no upfront costs or long-term commitments. This makes it cost-effective, especially for small businesses or startups that want to minimize infrastructure costs.
Data Accessibility: S3 allows easy and secure access to data from anywhere on the web. It provides a simple web services interface and supports various access control mechanisms to manage user permissions effectively.
Integration with Other AWS Services: S3 seamlessly integrates with other AWS services, enabling businesses to build scalable and powerful applications. It can be used with services like AWS Lambda, Amazon Athena, Amazon CloudFront, and more, to process, analyze, and deliver data efficiently.
Security and Compliance: S3 offers robust security features, including access control mechanisms, encryption options, and logging capabilities. It helps businesses meet compliance requirements and ensures the confidentiality and integrity of their data.
Content Distribution: AWS S3 integrates with Amazon CloudFront, a content delivery network (CDN), allowing businesses to distribute their content globally with low latency and high data transfer speeds.
🌟 Different types of data storage in AWS S3?
You can store virtually any kind of data, in any format, in S3 and when we talk about capacity, the volume and the number of objects that we can store in S3 are unlimited.
*An object is the fundamental entity in S3. It consists of data, key and metadata.
When we talk about data, it can be of two types-
Data which is to be accessed frequently.
Data which is accessed not that frequently.
Therefore, Amazon came up with 3 storage classes to provide its customers the best experience and at an affordable cost.
In AWS S3 (Amazon Simple Storage Service), different storage classes are available to meet various data storage needs. Here are the different storage classes in S3 with real-time examples:
S3 Standard: This storage class is suitable for frequently accessed data and real-time applications. For example, a popular e-commerce website stores its product images and website assets in S3 Standard to ensure fast and reliable access to the images for customers browsing the website.
S3 Intelligent-Tiering: This storage class automatically moves data between two tiers based on access patterns: frequent access and infrequent access. An example could be a media streaming platform that hosts a vast library of video content. Frequently watched videos are kept in the frequent access tier, while less popular videos are moved to the infrequent access tier, optimizing costs without sacrificing performance.
S3 Standard-IA (Infrequent Access): This storage class is ideal for data that is accessed less frequently but requires rapid access when needed. For instance, a data analytics platform that stores large datasets for periodic analysis may use S3 Standard-IA to efficiently store and retrieve data during analysis runs, while keeping storage costs lower compared to S3 Standard.
S3 One Zone-IA: This storage class is similar to S3 Standard-IA but stores data in a single Availability Zone. It is suitable for scenarios where data redundancy is not a critical requirement, and cost optimization is a priority. A backup system that stores infrequently accessed data in a single region could use S3 One Zone-IA to save on costs.
S3 Glacier: Glacier is designed for long-term data archival with lower storage costs. A financial institution might use S3 Glacier to store historical transaction records that need to be retained for regulatory compliance purposes. Although the data is rarely accessed, it can be retrieved when required for auditing or legal requirements.
S3 Glacier Deep Archive: This storage class offers the lowest storage costs and is suitable for rarely accessed and highly cost-sensitive data. An example could be a research institution that archives large volumes of scientific data, such as genomic sequences or climate data, for future reference. These datasets may have minimal retrieval requirements but need to be stored for extended periods at the lowest cost.
🌟 Steps to create an S3 bucket
- First create an account on AWS. You can create AWS Free Tier on AWS Cloud, you can create a Free Tier account by going to Google, searching for AWS free tier account and follow the link.
You can create new account by following the link and after that it will ask you for your information; just follow the steps and you are ready to go. It will ask for your card information but its free, so you won’t be charged for anything if you use only AWS free Tier limit. Or if you already have one you can simple login to your account.
I already have one, so I am going to use my account.
After you logged in go to your AWS console and look for service S3. You can search for S3 in the search bar or can find it simply by clicking on Services on the left top.
- AWS console screen with recently visited services.
- On the AWS console screen click on S3.
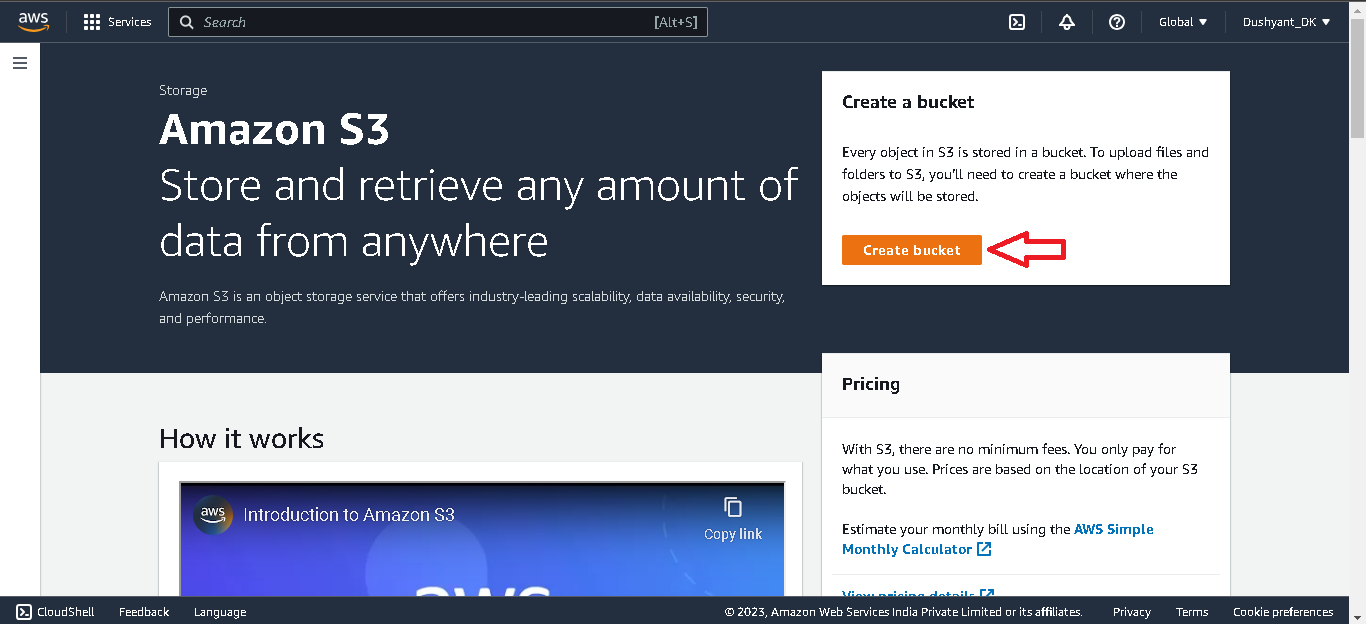
On the Console Screen create a bucket.
This screen will show up. Click on Create Bucket button.
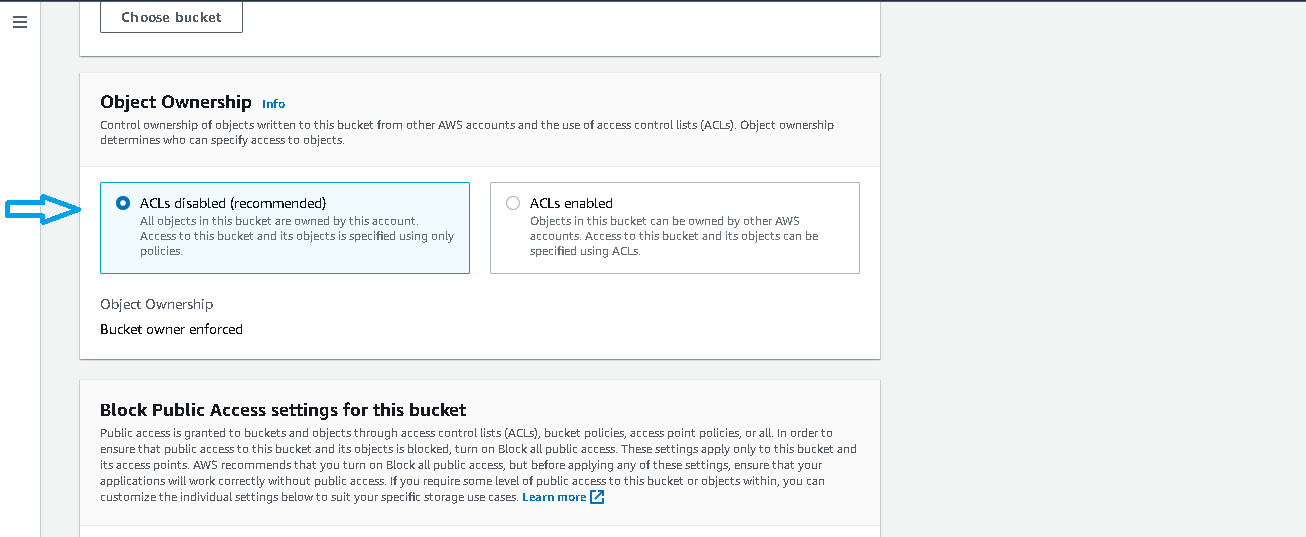
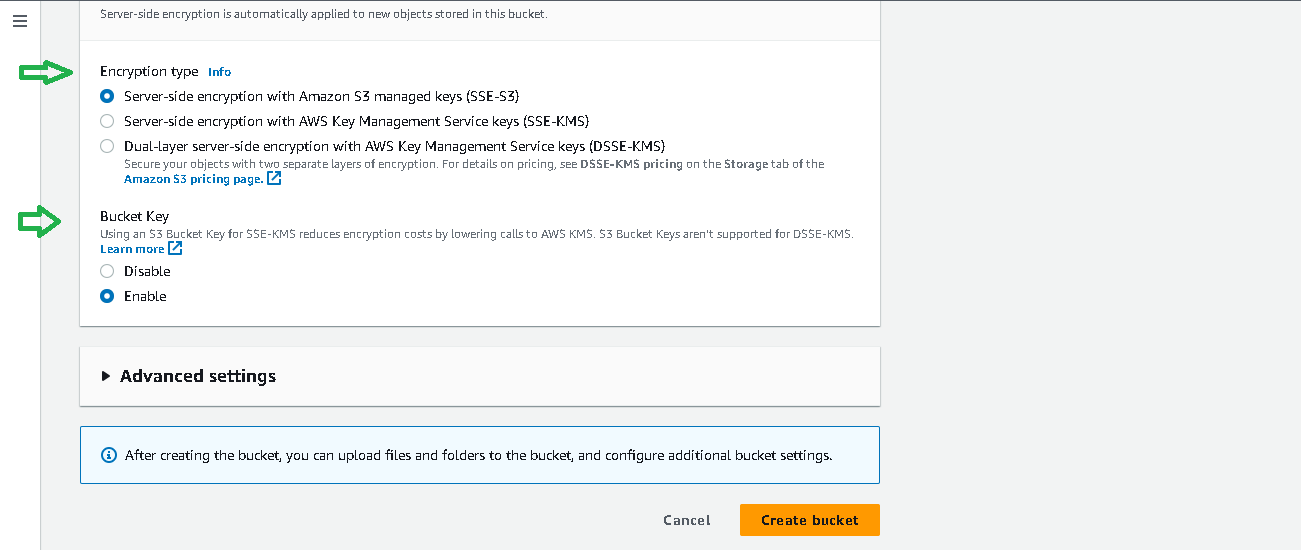
- After clicking on Create Bucket Button you will see the screen like this. Just fill in the bucket name and don’t change any permissions and click Create Bucket button at the bottom of the screen.



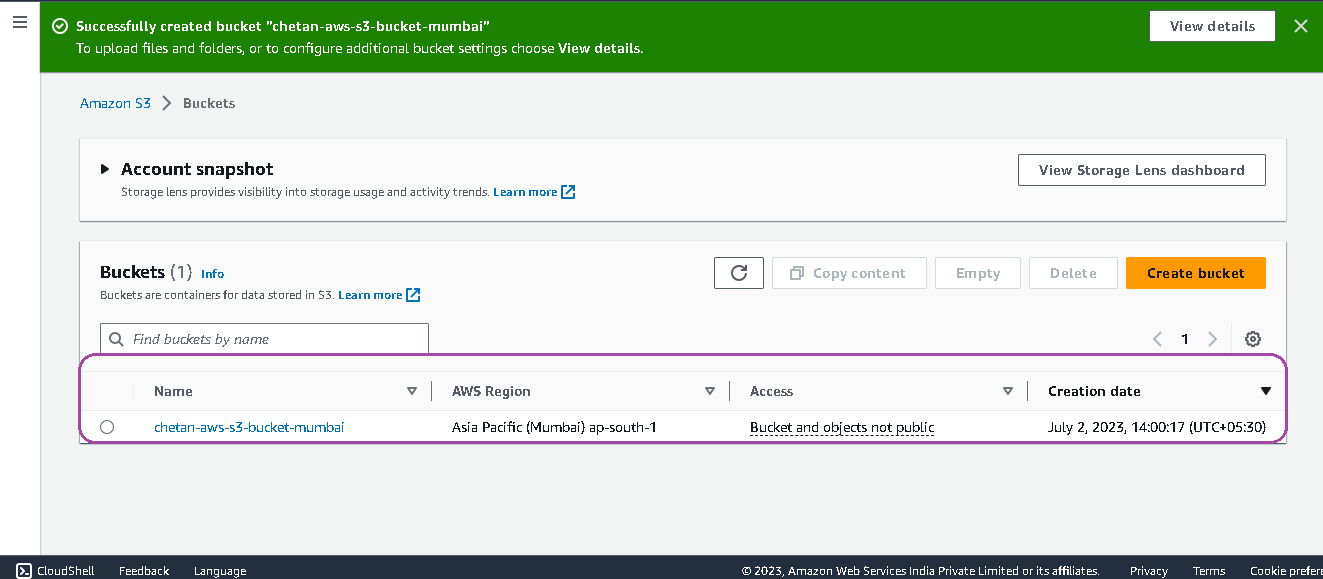
- After that, you will see all the created buckets here. Now click on the recently created bucket to upload your website or image.
- Click on the recently created bucket, you see it empty now it's time to upload files/folder AWS S3 Buckets list.

- Here in the selected bucket, you can upload your folder or simply drag your folder here to upload files It will take some time to upload all your files, so wait.


- Now your file uploaded successfully.
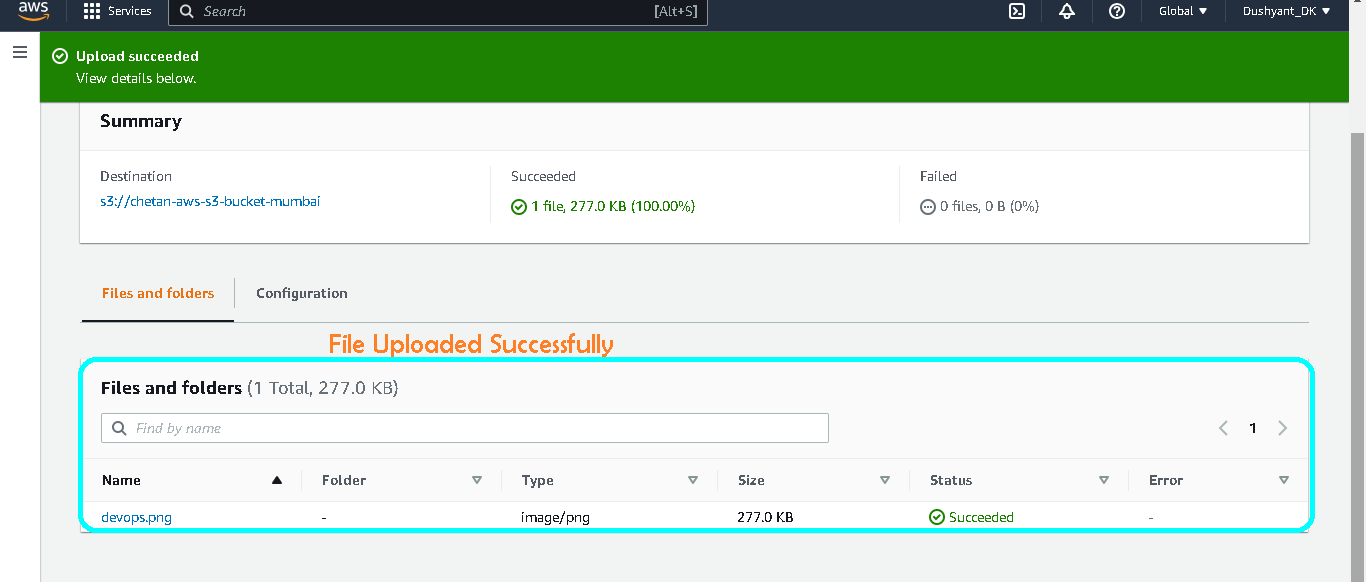
- Refresh your web browser and now you see your object in the bucket.

- You will see your output as an image as an output.

🌟 Conclusion
S3 is a core service of AWS Cloud Computing. Here we saw what is AWS S3, why we need AWS S3 and different types of data storage in S3. We also do a hands-on lab on how to create an s3 bucket, and how to upload files such as images. If you want how to access the AWS S3 bucket using AWS CLI refer to the blog link below.
Thank you for reading this blog. If you found this blog helpful, please like, share, and follow me for more blog posts like this in the future.
\...................................................................................................................................................
The above information is up to my understanding. Suggestions are always welcome. Thanks for reading this article.
#aws #S3 #awscloud #DevOps #TrainWithShubham
#90daysofdevopsc #happylearning
Shubham Londhe Sir
Follow for many such contents:
LinkedIn: linkedin.com/in/dushyant-kumar-dk




